
1.4/50 Summilux ASPH, Leica M10P, RAW
(これは次のblog postの続編です。)
kaz-ataka.hatenablog.com
機械学習ベースのAIの生み出す結果について問題提起的な議論を聞くことが多い。
〇〇についてしらべると
- 極端に男性に偏っている
- 極端にヨーロッパ系の人たちに偏っている
- 極端にリベラル(英語圏の意味の左派)よりである
- 豊かな人達に向けた議論があまりにも多い
- 体型や容姿に恵まれた人への極端な偏りを感じる
などなどだ。
気持ちは大いにわかるが、機械学習というものの特質を考えると致し方ないところは多い。機械学習ベースのAIは7-8年前にHarvard Business Reviewで整理したとおり、相当の計算環境に、テキスト処理や機械学習を含むアルゴリズムを実装し、大量の経験値を与えて特定の目的に向けて訓練したものだからだ。
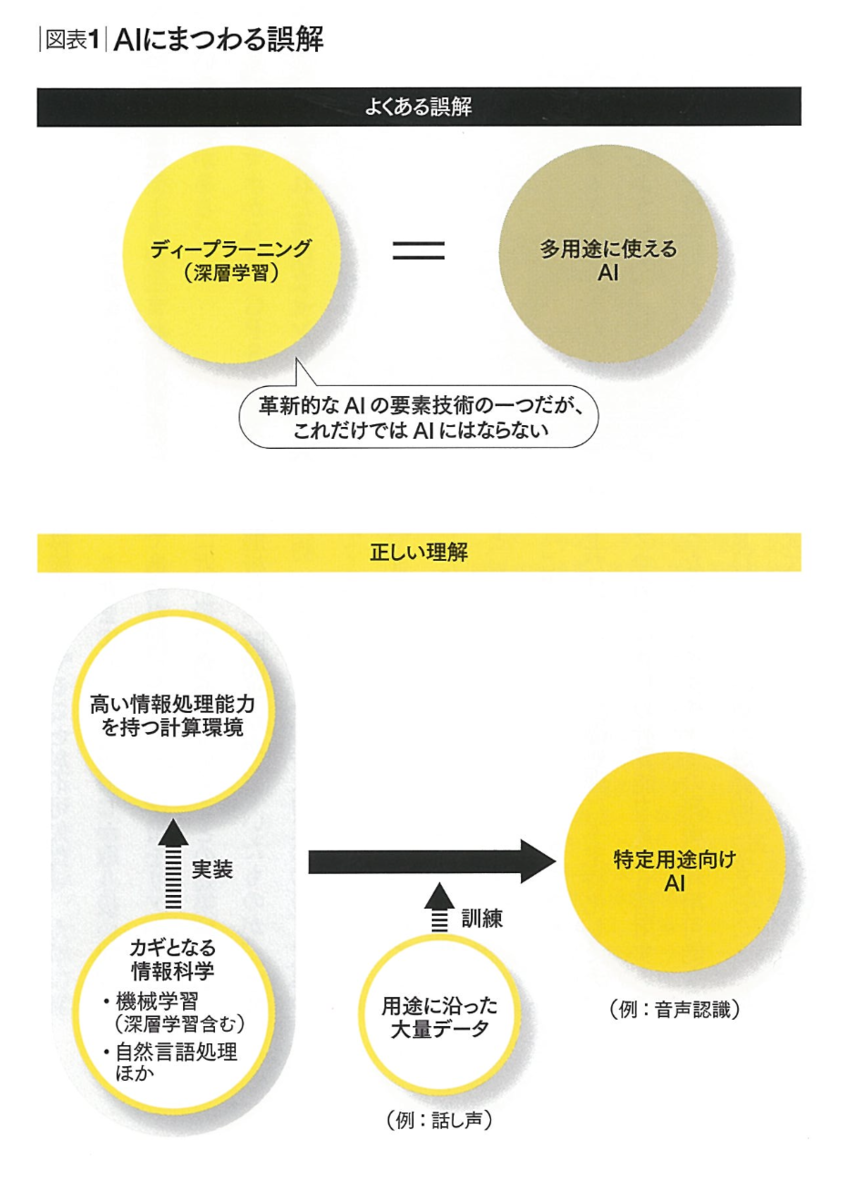
安宅和人「人工知能はビジネスをどう変えるか」より(Nov. 2015, Diamond Harvard Business Review)
大量の経験値は、結果が出るゲームやマニピュレーション(ピッキングや運転など)のようなものであれば実戦(バーチャル空間を含む)で良いが、多くの場合は、既存のデータが用いられることが多い。
既存のデータは二重の意味で使う側からするとちょっとした課題がある。
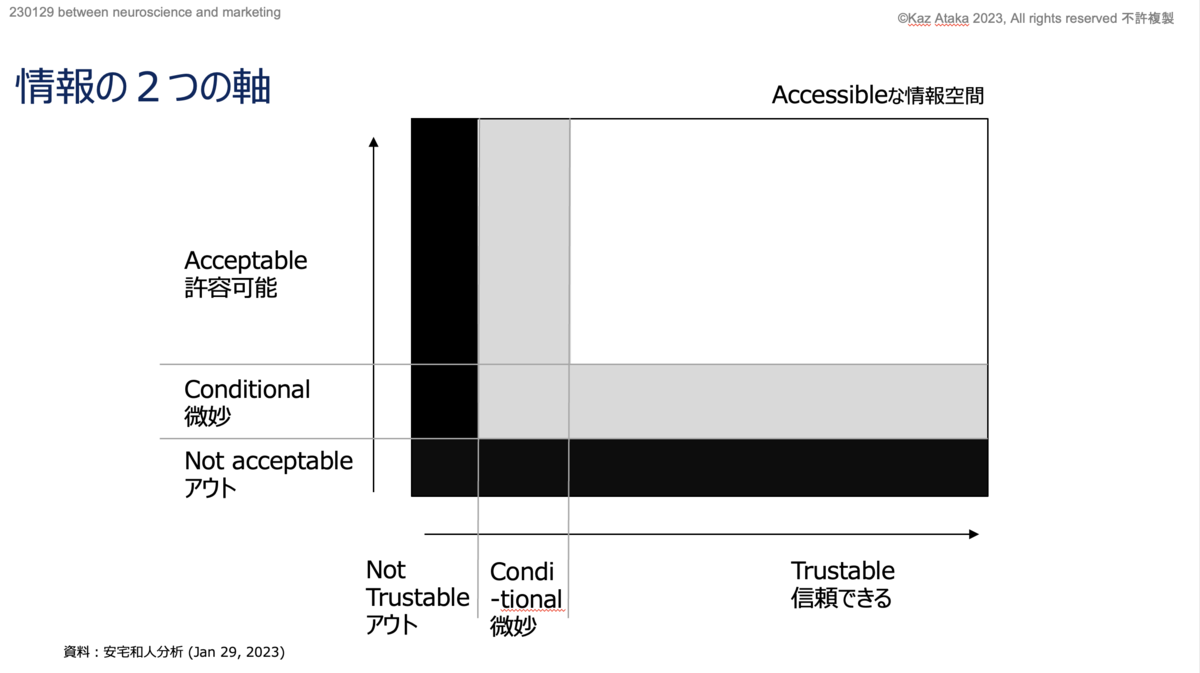
第一に必ずしも事実として正しくないものが大量に含まれている。情報の信頼性と言うべきものであり、英語で言えばtrustworthy (trustable) かどうかだ。
第二に事実としては正しいけれども社会的に許容されないものが大量に含まれている。これは情報の社会的正義性というべきものであり、英語で言えばsocially acceptableかどうかだ。
最も大量に使われている機械学習ベースのAIツールという意味で検索(Search)を例に取ると、第一の課題は検索が生まれたときから続く本質的な課題だ。
これについては政府など出自が確実な情報サイトに加え、Search誕生当時、もっとも人手をかけて信頼性が担保されていたYahoo! Directoryに載っているサイトなどがindexingされ、その上で、Larry Page氏が考案したPage rank(Page氏の名前とサイトのページを掛けた命名)システムにより当初立ち上がった。今でも情報源の利用される度合い、サイトの信頼性、記事を生み出した人の信頼性を相当に幅広く、そして深くratingしていることはほぼ間違いない。
ちなみにWebの前はそもそも出版社、新聞社、TV局ぐらいしか多くの人に情報を提供できなかったために、メディア側の選択による情報の偏りは大いにあったと思うが、中身の信憑性はある程度以上に担保されていた。一方、Twitter、YouTube、Tiktokに代表されるソーシャルメディア化が進む現在では相当の情報が怪しいという意味で情報空間は劇的に変化した。
GoogleやかつてのYST(Yahoo! Search Technology)、そしてBing、Baidu、Naver、Yandexは長らくten blue linksとよばれるウェブ面で最初に出てくる情報に欲しい(関心にrelevantな)、役に立つ(useful)、可能であれば鮮度の高い(fresh)情報が必ず含まれることを担保するために膨大なエネルギーを注いできた。25年以上前のwebサービスを利用した人であれば、機械検索をした場合、数ページ以上もスクロールしなければ、欲しい情報にたどり着けないことが普通だったことをよく覚えているだろう。みなさんの膨大な検索履歴がこの結果を磨き上げてきたと思えばこれは10億単位の人の無限の取り組みによる人類の偉大な建造物と言える。
-
第二の課題はあまり議論されないが社会正義的には相当に大切で、また相当に難しい問題と言える。これは最近であればDiversity, Equity, and Inclusion(DE&I)と呼ばれる話が直結している*1。直訳すれば「多様性、公平性、包括性」なわけだが、この中身で問題とされているものが時代とともに急激に変わってきたからだ。
50代前半の自分が子供の頃は、正直、社会的に大きく話題になるDE&I的な話題は5つぐらいしかなかった。
第一に優生学(eugenics)的な差別。ナチスドイツで有名になったが、実はプラトン以来の話で極めて根深く、これが実際のところ他の軸にも覆いかぶさっている。末期は単に堕胎を認めるためのものとして形骸化していたとはいえ、日本にも1996年まで優生保護法があったことの罪深さは大きい。断種された方々やその周囲の方々の苦悩は僕には到底語ることはできない。
第二に人種および民族差別、特に黒人解放問題。植民地・奴隷制度時代の記憶が混ざっており、更に根にあるのは自分たちとはそれぞれが違うという問題で異質の受容性の問題だ*2。戦前の米国での黄禍論、日本における在日差別問題もここに含まれる。
第三に女性差別。女性解放(Woman liberation)や米国で1960年代末に一気に始まった男女共学化(co-education)はこの話だ。仕事による男女の雇用や昇進差別問題はここに含まれる。*3
第四に貧富問題。現在Social Divideと呼ばれている問題だが、貧しさの中から這い上がるタイガーマスクや巨人の星などは大きな社会的な意義をもって放映されていたと推定する。
第五に国家の差別。南北問題に代表される問題だ。人種・民族差別問題と絡み合うことが多い。
-
これが現在であれば、eugenics的な考えがもたらす課題は、パラリンピックに見る通り、様々な障害を持つ方々の活躍や権利が当然になる一方(素晴らしい進展だ)、実は今もデザイナーベイビーや遺伝子治療の関連で課題が復活しつつあり議論は相当に入り組んできている。何がどこまでsocially acceptableなのかの見極めはかなり難しい。
Raceというのは生物学的には意味のない概念であり、これによる差別の撤廃に疑義を唱える人は表立っては絶滅したが、実にしぶとく、まだまだ問題を廃絶できていない。その結果、かつてとは比較にならないほどセンシティブな問題になっており、表現においてacceptableな領域は極めて狭くなっている。部族問題は当時は大きな議論にならなかった隣国の話が大きな政治課題だ。
Gender parity問題は解決すべき課題と日本でも流石に認知されつつあるが*4、現在、gender問題にはLGBTQに代表される性的マイノリティの問題が当然含まれる。日本の性別区分、男/女は相当に遅れており、female, male, non-binary, prefer not to say(女性, 男性, それ以外, 言いたくない)が世界の標準だ。ここでもかつての常識は許されなくなっている。
かつて広告に出てくる人の体型など問題視されたことはなかったが、Tyra Banks, Naomi Campbell, Miranda Kerrなどスーパーモデルを輩出したVictoria's Secret(米国を代表する女性向け下着ブランド)ですら、彼女らAngelsプログラムを2018年に廃止し、ユニークな経歴、興味、情熱を持つパートナーにスポットライトを当てるVS Collectiveに移行した(大坂なおみ選手もその一員)。広告に出るのはスタイルの良い美男美女ばかりというのはすでにアウトであり、Body Diversityはもう不可避な流れと言える。*5
Divideの話は深刻さをむしろ増しているのにも関わらず大っぴらに議論されることは憚られる謎の風潮がある。併せて、関係は微妙であるが飲酒行為やタバコにまつわる許容性も劇的に小さくなった。
国家の差別については、シンガポールに代表される東南アジア、中国、インド、ブラジルなど中南米諸国、いくつかのアフリカ諸国の繁栄とともにだいぶ改善されつつあるが、その結果、これらの国々に対する表現として許されるゾーンは激変した。一方で911以降のタリバン、IS関連の問題などは逆に当時なかった問題がテロと国際政治を起点に発生している。
当時気にする人など殆どいなかったAnimal rightも今や相当にセンシティブな話題であり、1990年代(30年前)の感覚で迂闊なことをいうと地雷を踏むことになる。
つまり30-40年前とは全く別の世界と言っても良い状況だ。かつて許容されたことの多くがもう許されないのだ。*6

とはいうものの、世界のデータをそのままスキャンして写し絵をとると、これらの社会の記憶がまるごと写し取られる。
それは今の目から見ると「政治的に正しい/社会的に許容可能である (politically correct/socially acceptable)」ではない情報が溢れている世界が写し取られるということだ。デジタル化されている情報が偏っているだけの話ではない。情報のTrustabilityだけでなく、DE&Iのホワイト、グレーゾーンが実際にはmoving target(動く標的)であり、このacceptableな境界線は時間とともにダイナミックに動いているからだ。つまり機械学習ベースのAIからこの課題を完全に排除することは事実上不可能と言って良い。
機械学習ベースのAIとしては、trustableそうな情報はすべてを一旦飲み込む、それをデータの重要性(データの分布や人が使うかどうか)という視点で提供する。これは検索においてもそうであるし、ChatGPTのような大量言語モデル(LLM)ベースのAIについてもそうだ。しかし、その結果は、社会の歪みで汚れているだけでなく、社会の動く基準の両方によって、ある種よごれているということだ。
ただ、犯罪に絡む言葉、差別用語を辞書から剥ぎ取ることができないのと同じく、これらを剥ぎ取るとたとえば検索の機能は相当に使えないものになる。第一にそれ自体が調べるに値する情報であり、第二に詳しくは割愛するが、検索ワード(クエリ)の大半は年に一度も使われるかどうかという代物の巨大なロングテールといってもよい情報であり、これらに対して答えが出るかどうかで検索利用者の満足度が大きく変わるからだ。
ということでAIのもとになる情報源にはこの2つの軸でnot acceptableなものが入り混じっていること、双方の軸が相当に動いていること、したがって完全にクリーンなツールを作ることはできないことまでは、現代における情報利用のリテラシーとして深く理解をしておく必要がある。
子供に対してもちゃんと教えるべきであり、はじめは子供向けの検索でいいかもしれないが、中学校に入るかどうかぐらいから大人向けの検索を開放しなければ彼らの関心にうまく答えられなくなる。その段階で繰り返し、事例をもとに機械学習の原理とともに課題とリスクを話し合うような場が必要だ。

ここまでで少々お腹いっぱいかもしれないが、Trustable/Acceptableに加えて、あと2つの提供される情報に関する軸をheads-upしておきたい。
一つは、これは本人が余り意識していないかもしれないが、利用者の志向というか性向による偏りだ。これが第3の軸になる。機械学習はあなたの利用特性をどんどんと吸収し、あなたの好む結果をどんどんと出してくるのだ。いわゆるパーソナライズだ。
パーソナライズと言っても個人に対して行っているとは限らない。言語によっても地域によっても起きる。「災害」と"Disaster"は異なる処理がされているということだ。これは課題と言っていいのかわからないが、明らかに情報の偏りを生じさせる。興味深い事例として、IDのタグ付を外すために、ブラウザでシークレットモードの画面を立ち上げ、そこで Beautiful woman、美しい女性、खूबसूरत महिला(ヒンディ語)と画像検索をして頂ければどれほど違う結果が出るかわかるだろう。
このような言語、地域、社会的な文脈に加えて、自分がどのような検索結果を選んでみているかによる偏りが重なってくるということだ。自分が見ている検索結果や、Chatbotの返答は一般的なものではないという認識を相当強く持っていないとこのフィルターバブル*7、あるいはエコーチャンバー*8的な問題を認識することは困難だ。本当はログインなしで検索などは続けたほうがいいのかもしれない。
最後に、4つ目の軸として、その情報の背後にある社会の本音度というのがある。たとえば前国務長官のヒラリー・クリントン氏とドナルド・トランプ氏が戦った2016年の米国の大統領選では下馬評ではクリントンという声が強く、人に聞いてもクリントンに入れるよという人が多かったわけだが、実際にはトランプがかなり明確に勝った。この軸こそが情報を見るときに大切だという話が先日、Pixie Dust社(PXDT)のイベントで代表の落合陽一氏から出て、たしかにと膝を打った。この落合軸というか本音度は相当に大切だが、これはいま我々が見ている情報や、それを飲み込んだ機械学習の結果にどのように出てきているのかはよくわからない。今後研究が必要になるだろう。
-
機械学習ベースのAI時代に求められるリテラシーとして、その背後の話とその情報吸収の意味合いについて、ちょっと整理してみた。写し絵を飲み込んだAIは僕らの生み出した最大級の知的資産の一つではあるのだが、そこには相当に理解を深め、留意しておくべきことがある。それを知った上で使い倒せるようになりたいものだ。
Have fun!!
ps. DeepLとDeepL Writeを活用し、英語版も作りました。FYI
kaz-ataka.hatenablog.com
*1:タバコやアルコールのようなそれ以外の問題ももちろんある
*2:帝国主義、中華思想的なものはすべからくこの傾向がある。かつて大日本帝国を名乗っていた日本も相当に色々深く反省し未来に生かさねばならない。
*3:日本はなぜか立ち遅れているが、男女は共に同じ教育機会を得られるべきであり、社会的にも同じrepresentationを持つべきであるということは疑義のない正義のはずである。この観点に則って、もともと全寮制の男子校であった米国東海岸の名門大学たちは軒並み1960年代後半に門戸を開き、20世紀末以降はgender parityを実現している。本来は共学の小中高で1:1で定員を当てている通りのことが、基本高等教育や職場、特に意思決定層でもおきなければいけないというのが世界のコンセンサス。前駐日米国大使が女性だったり、メキシコでは国会ですらgender parityが実現される中、日本の国会はいまでも1割しか女性がいない。
(参考)Times Higher Education : World University Ranking 2023 : Gender ratioは基本的な評価項目であり、サイエンス、工学にフォーカスしたCaltechやMITですら女性が4割である。ちなみに男女比ではなく、女男比。これが世界の標準。

*4:先進国の大半ではほぼ解決しつつあるが、注釈のとおり日本は何周か遅れている
*5:日本のTVのバラエティ番組における一般庶民の代表としてのお笑い芸人はこの観点で大きく貢献している。
*6:なお、日本では「臭いものに蓋」文化のせいで、この大半が、議論して都合の良い物(障害者雇用や女性役員の数など)以外は、ほとんど正面から議論されていない。そのためにこの国が世界の主要国からは数十年遅れた意識になっていることは、特にリーダー層の方々は相当に認識したほうがよいだろう。また、自分の業務や会社がどのような状況かをチェックすることを強く推奨する。実際、僕も数年前に赴任直後の北米からのとある駐日大使に様々なこのDE&I的な属性での日本の異様な遅れについて数時間、大使館でガンヅメサれたが、自国の現状に本当に泣きたくなるほどだった。
*7:特定の情報フィルターを通った情報だけの泡の中にいる現象
*8:音が反響する部屋