
1.4/50 Summilux ASPH, Leica M10P, RAW
Midjourney、ChatGPTと立て続けに強烈なアプリケーションが出てきて、Diffusion model(拡散モデル)やtransformer architectureに基づくいわゆるGenerative AI(生成系AI)がそこらで話題だ。ガンガン画像を生み出すことで一気に注目を集めたMidjourneyはクリエーター寄りだけれど、11月末、対話型で答えを返してくれるChatGPT*1が出てきたときに*2、あまりの回答力にDS協会*3のスキル定義委員会でもひとしきり話題になり、僕も自分の研究会の学生たちに「君ら、深く考えずにまずは使い倒したほうがいいよ」と早々にアドバイスした。使わないことには凄さも課題も何もわからないからだ。
すると二週ほど前のゼミで、ある卒業を控えた学生が
ChatGPTがないと生きていけない。課題もメールも全部やらせている。SQLも図の作成もできる。ただ、論文を引用してくださいと聞くと架空の論文を生成して引用してくるのでこれだけは使えない
と宣う(のたまう)ではないか。本当に彼は文字通り「新たな召使い」としてChatGPTを使い倒し、codeも書かせ、翻訳もやらせ、レポートも下書きを書かせ、めんどくさい相手へのメールの返事も書かせている。論文を引用させて、それが本当には存在しないものをでっち上げているところもちゃんと見破っている。なかなかである。*4
並行して、米国医師資格試験(USMLE)をChatGPTに解かせてみると、特殊な訓練なく合格かそれに近いレベルのスコアで、説明の一致度や洞察も高かったという報告が出てきた。信頼できる情報が揃っている医学との相性がいいのは当然としても知的プロフェッショナルの訓練と未来に大きく関わることは間違いなさそうだ。
かと思えばStanford大学ではかなりの数の学生がすでにChatGPTを使っているという。まだ現れて1ヶ月あまりの1/9 ~ 1/15まで実施された匿名調査によると(N=4,497)、学生の回答者の約 17% が、秋学期の宿題や試験にChatGPT を使用したというのだ。5日ほどまえの学生新聞(The Stanford Daily; 1892年創刊)の記事だ。
シリコンバレーのど真ん中にあるStanfordとしては当然だろう。
大学スポークスパーソンのDee Mostofi氏は
学生は「許可されていない助け」なしにコースワークを仕上げることが期待されており、「許可されていない助け」は多くの場合、ChatGPTのようなAIツールを含んでいる(“Students are expected to complete coursework without unpermitted aid,” “In most courses, unpermitted aid includes AI tools like ChatGPT.”)
と記事内で語っているが、この不連続性の高い局面においては、単にルールを守って知らないままでいるよりも、使って使ってそれで意味合いを誰よりも身体で掴むことのほうが未来を生み出す人たちにとって大切だからだ。
SF Bayの向かいのライバル校である UC Berkeleyでもきっとそうだろうし、この二校とならびComputer Scienceの4大メッカと言えるCarnegie Mellon(CMU)、MITでもそうだろう。
そして現在、ちょっとした節目ということでMicrosoftはこれの大元であるOpenAIに大きな投資をすることを発表した。この意味合い自体が業界的にはかなり興味深いが本稿では割愛する。
-
話を戻すとこのような生成系AIツールの出現は、教育も仕事も何もかも変化が必要だということを示している(先日ちょっと話題になったリンク先のTweetでも書いた)。人工知能が急激に話題になり見立てが混乱していた七年あまり前、AIをどう考えたらいいのか、その意味合いも含めて議論を整理してほしいとの依頼を受けて書いたとおり、人間は生まれた技術を何もかも使い倒す生き物だからだ。

20世紀末にパロアルト Stanfordのキャンパスで「検索(Search)」が生まれたときも、ただ答えを出すということの価値は消えつつあると相当に言われたが、これは本当にそういう時代に更に突入したことを示している。この視点で見ると決まった答えがあるケースにおいて問いを多々与えて、早く正確な答えを出すことを競う今の教育は本当に無意味な世界に近づいている。それはキカイのほうが得意であり、キカイに任せる時代により一層突入してしまうからだ。(逆にとっかかりすらない問いについて掘削する力はこれまで以上に大切になる。)
上のStanford Dailyの記事によれば「宿題の一部でもAI agentを使ったらちゃんと資料として使ったことを明らかにすること(If you choose to use an AI agent for generating portions or aspects of an assignment, you must disclose this use and cite it in the same manner as you would cite any external source)」と課すクラスが現れ、紙と鉛筆の試験に戻した先生もいるとある。確かに医学における解剖学のような知識を頭に詰め込んでおかないといけないと現場での即座の判断ができないことは多々あり、この辺りの高等教育現場の混乱はしばらくは続くと思うが、1-2年もすると概ね落ち着くだろう。
それはそれとして、この変化は意味のある問いを立てる、生み出された答えを評価し、更に正しく問いや指示を与えるという能力が決定的に大切になったということを意味している。本当の意味で教養の時代に突入したということでもあり、これはかつて知性の本質について考察した際に結論、また中核概念として述べた「知覚」の磨き込みの時代に突入したということでもある。


多様な価値や美しさを複合的にそして生々しく理解できる力があるか、それに基づく美意識、〇〇がほしいという心、これではダメだとわかる皮膚感覚、、この辺が本当に勝負になる。なでて、なめるなど、身体で深く生々しく感じることがその起点である。
ほぼ真逆の教育をメインに行なっている日本の初等中等教育は、劇的と言っても良い変化をしなければ、年始のWeekly Ochiaiで落合陽一氏と語り合ったとおり、本当に「High IQのただ使役させられる人」を大量に生み出す装置になる可能性がある。学生たちが勝手にハックする部分が多いとはいえ、小中高で相当の自由度が与えられなければ、問いを生み出したり、自分なりに感じ評価する力は相当にダメージを受けるだろうということだ。
-
使ってみればすぐに分かるが、ChatGPTは、いわゆる「検索」とは大きく異る。クエリと言われる知りたい言葉を打ち込む(= 検索のような)使い方もできなくはないが、それはこの大量言語モデル(Large Language Model: LLM)に基づくツールの能力を解き放つものとしては微妙だ。なぜなら、そういうことは検索のほうが得意で正確であり、LLMベースのツールのほうが圧倒的に得意なことが別にあるからだ(あたかもなんでも答えられるAIかのようにMetaが投入したGalacticaが3日でちょっとしたお休みに入ったことを覚えている人もいるだろう)。
現在最も使われているAIベースのツールといっても良い「検索」は答えがあることを叩き出すのには極めて強い。世界中の裏までも探して、一瞬で答えを出してくれる。しかも信頼性が高い。実際にはデジタル化された情報を信頼性を見つつ事前に調べ上げ、それを整理しているのだが *5 うまくやれば*6衝撃的な速さで欲しい答えにたどり着くことができる。
ただ、なんとなく知りたいことだとかやりたいが何をしたらいいのかよくわからないこと、つまりこれまでは自分で頑張って考えるか、よく分かる人を巻き込まないと得られなかった答えの大まかな方向性がChatbotであるChatGPTでは得られる。しかもリアルタイムで答えが生み出される。これがなんというか人間に聞いているときのような独特の感動がある。毎回違う答えが生み出されるのも良い。適切に指示さえすればコードを書かせることもできる*7。
このようなテキストだけでなく、画像や音楽などの生成系全般に言えることだが、この新たなキカイが何かを生み出す速度は人間とは比較にならないほど速い(Weekly Ochiaiの落合氏のデモを参照)。これは何というか大量の弟子を持っていて、指示と仕上げにエネルギーを注いでいたミケランジェロに近い状態に多くの人が近づいているということだ。
問題は必ずしも正しくないことが語られること、僕の学生が指摘しているようになんというかでっち上げる、あるいは類似したものでつなぎ合わせてしまうことが多々あるということだ(生成系そのものが考えようによれば本質的にクリエイティブである)。論文もそうであるし、事実もそうだ。僕が上の画像の積み木(tsumi-isi)を入手したとき、「賽の河原とシーシュポスの神話の類似性と違いを教えて下さい」と聞くと次の答えが得られた。なかなか興味深い回答であるが、これは仏教的な世界観である賽の河原とギリシャ神話(シーシュポス)、エジプト神話を明らかに混同している。

ただこのことはLLMにおいて多くのフレーズや意味が多次元空間におけるベクトルとして表現されていることを考えれば半ば致し方ないことと思われる*8。多次元空間での表象については、次のGoogle translateに関する発表を見ていただければ多少イメージが湧くだろう。
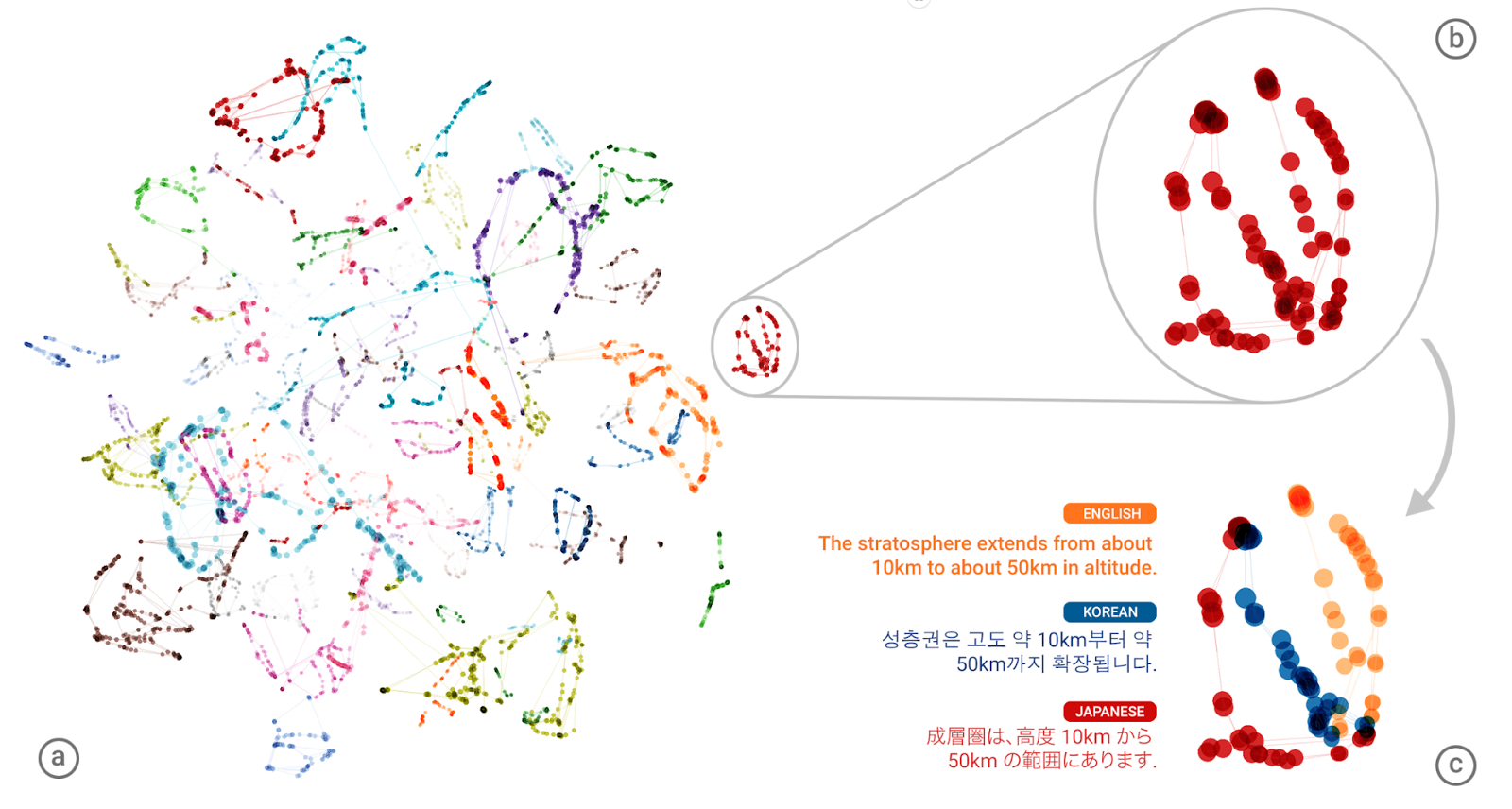
論文リンクhttps://arxiv.org/pdf/1611.04558v1.pdf
しかし「賽の河原」が「シーシュポス」と相当にベクトル空間的に近い概念であると言うこと自体がちょっとした感動すら覚える。人間同様の類似性の発見とそこからの意味合い抽出、その延長にあるある種の思いつきとアナロジーからの発想まであと数歩だからかだ。
実際、先程の記事のStanfordの学生たちでChatGPTを使った学生たちの最大用途(約6割)はブレストの相手としての活用だ。だいたいのことで識者や詳しい人間が近いはずのStanfordの学生といえども、こんな大学の宿題みたいなもののために人に尋ねるわけにはそうそういかない。しかし僕らの日頃の思いつきってほとんどどうでもいいことから始まることがほとんどだ。しかも即座に尋ねて、ほぼ即座に何かが返ってくるのだ。雑な回答というのも悪くはない。人間はもっと雑だしもっと適当なのに、十分コミュニケーションは成り立っており、そんな対話から面白い何かが生まれてくる。
これってなにかすごいことにつながっている気がするのは僕だけではないだろう。
普通にはつながらないものをつなげてさらに何かを妄想する、それが僕の最大の喜びの一つだが、また一つ新しい道具が手に入りつつある。
さあ新しい道具を手にしつつ、生の世界に帰ろう。
ps. 続編はこちら。
kaz-ataka.hatenablog.com
ps2. DeepLを活用し、英語版も作りました。
kaz-ataka.hatenablog.com
https://amzn.to/40ch0Xhamzn.to
www.designofficea4.com
*1:OpenAIから生まれたAIチャットボットの一つ
*2:テスト公開は12/1。一週間以下で100万人以上が使用
*3:データサイエンティスト協会
*4:この学生は学部二年でとある情報系の名のある学会で奨励賞をもらったような輩なので、それなりのリテラシーはある。
*5:「検索(Search)」には意図把握、答えの準備と事前整理、意図と答えの意味的なマッチング、人にわかるように出す、という大きく4つのAI的なステップがあり、「答えの準備と事前整理」にはサイト評価、indexing、knowledge graph作成、それに基づくknowledge panel作成などの様々なすさまじい量の活動がリアルタイムで行われている
*6:複数の単語を並べたり、引き算的なことなどの技によって恐ろしく快適になる
*7:たとえば株式会社Works Human Intelligenceの@autotaker1984氏による次の論考を参照 ChatGPTによるプログラム生成の可能性と限界(前編) - Qiita ChatGPTによるプログラム生成の可能性と限界(後編) - Qiita
*8:実はもう一つ根源的な背景があるのだがそれについては別の論考で別途検討したいと思う